Turning data into actionable insights is a complex process for any business. Not only do many organizations have more data than they know what to do with, but they also don’t have the right processes – or staff – to leverage the data they possess.
The result? Unusable, raw data that contains errors, is incomplete, and can’t be relied on to make smart, data-driven business decisions.
Data munging is the first and most important step in turning this raw data into valuable insights, allowing businesses to optimize operations, identify new opportunities, and gain a competitive edge.
This article tells you everything you need to know about data munging, including what is it, how its stages, and how it can help businesses turn data into valuable insights.
What is Data Munging?
Data munging, also known as data wrangling, is the often-overlooked yet critical process of transforming raw data into a usable format for analysis. It's the bridge between the raw, chaotic state of data and the refined, actionable insights that drive successful business operations.
Data munging involves cleaning, structuring, and standardizing data to eliminate inconsistencies, errors, and redundancies. This transformation is essential for ensuring data accuracy, reliability, and compatibility with analytical tools, allowing organizations to leverage valuable data in their possession to make better business decisions.
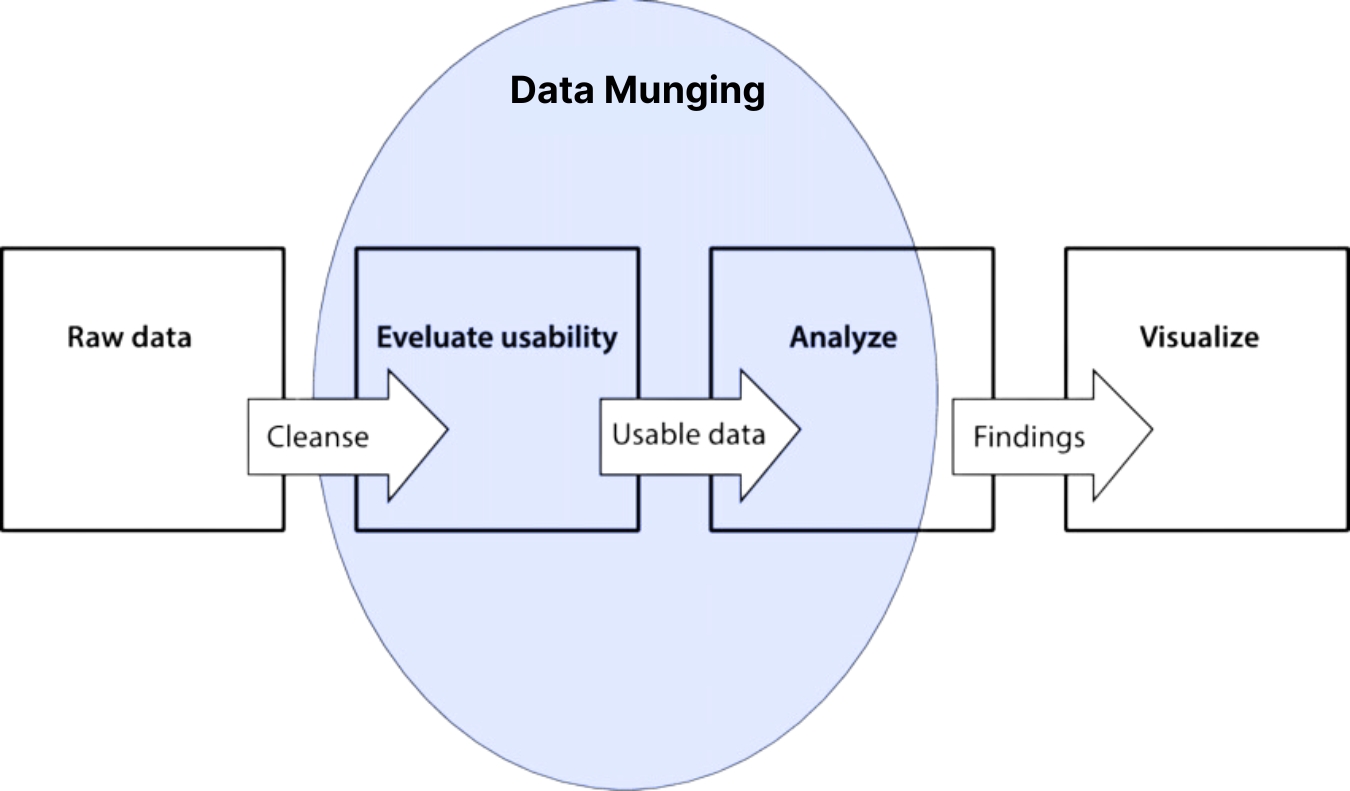
Without proper data munging, the downstream processes of data analysis, modelling, and visualization would be made impossible. In most organizations, 80% of the time spent on data analytics is allocated to data munging, where IT manually cleans the data to pass over to business users who perform analytics.
The process typically begins with a large volume of raw data. Data scientists will mung the data into shape by removing any errors or inconsistencies. They will then organize the data according to the destination schema so that it’s ready to use at the endpoint. is generally a permanent data transformation process.
Why is munging data important?
Data munging is the foundation for effective data analysis and decision-making. By preparing data correctly, it allows organizations to uncover hidden patterns, trends, and correlations that would otherwise be obscured by data quality issues. Ultimately, this leads to better decision-making, increased efficiency, and a competitive advantage.
Raw data is often plagued by inconsistencies, errors, and missing values. Munging data can eliminate these issues by cleaning and standardizing it, improving the reliability and accuracy of subsequent analyses.
Data munging is also necessary for data analysis. Raw data is often unstructured and incompatible with analytical tools. By transforming data into a structured format, data munging makes it easier for analysts to explore, visualize, and derive insights from the data.
Stages of Data Munging
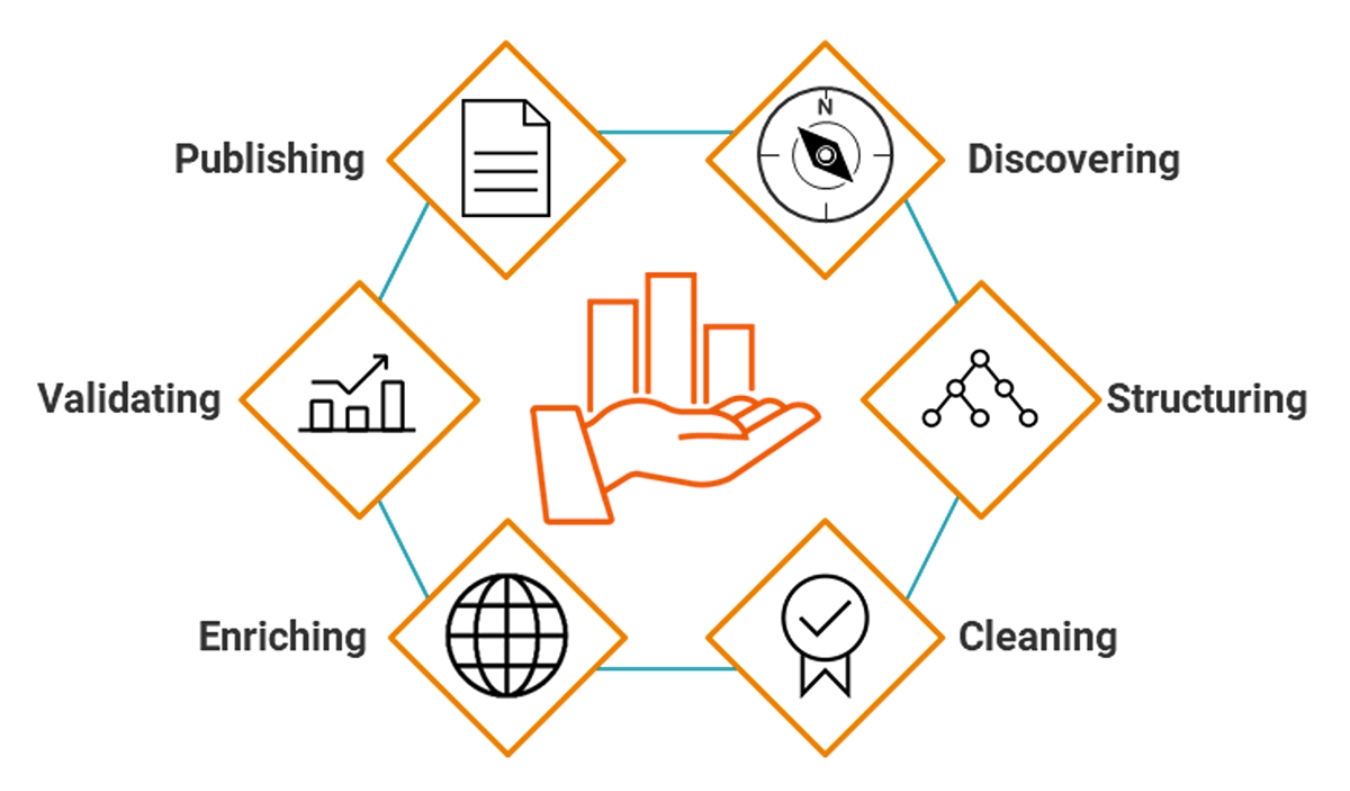
1. Data Discovery
Data discovery is the initial stage of data munging. It involves a deep dive into the dataset to understand its structure, content, and quality. Data analysts explore the data's format, identify variables and their data types, and assess data completeness. This exploratory phase is critical for developing a clear understanding of the data's potential and the challenges that may arise during the cleaning process.
2. Data Structuring
The next phase of data is data structuring. Here, the raw data is organized into a well-defined format, often in tabular form with rows and columns. This involves defining data types, creating consistent naming conventions, and ensuring data integrity. Data normalization, a crucial aspect of structuring, is also employed to eliminate redundancy and improve data efficiency.
3. Data cleansing
Once structured, the data munging undergoes a rigorous data cleansing process to address quality issues. This includes handling missing values through imputation or deletion, correcting inconsistencies, and removing duplicates. Outlier detection and treatment are also critical steps in this stage. The goal is to produce a clean dataset free from errors and anomalies that could distort analysis results.
4. Data Enrichment
Data enrichment is a crucial stage of data that helps enhance the data's value. The process involves incorporating additional information from external sources to provide a more comprehensive view. For instance, appending geographic data to customer records or adding product details to sales data can significantly enrich the dataset.
5. Data validation
Data validation is essential to verify the accuracy, completeness, and consistency of the processed data. This involves running checks to ensure data integrity and adherence to predefined quality standards. By rigorously validating the data, analysts can have confidence in the reliability of subsequent analyses and insights.
6. Publishing and orchestrating
This final process of data is publishing and orchestrating, which involves downloading and delivering the results of your data efforts to downstream analytics tools. Once you’ve published your data it’s time to move onto the next step, analytics.
Benefits of Data Munging
Data munging is a cornerstone of data-driven decision-making, offering a multitude of advantages for businesses of all sizes.. Primarily, it enhances data quality, identifying and rectifying errors, inconsistencies, and missing values, and ensuring that the data used for analysis is accurate and reliable.
Data munging also streamlines the analysis process. It transforms raw data into a structured format, meaning that analysts spend less time cleaning and preparing data and more time uncovering valuable patterns and trends. This is makes it ideal for advanced analytics, which require clean, structured data to produce accurate results to avoid issues like data drift.
By providing high-quality, actionable insights, data munging empowers businesses to make informed choices, optimize operations, identify new opportunities, and drive growth.
ETL vs Data Munging: What’s the Difference?
Both ETL (Extract, Transform, Load) and data munging involve transforming raw data into a usable format, but they serve distinct purposes and operate at different scales.
ETL is a broader, more structured process focused on data integration, while data munging a more granular a subset of the data transformation phase that focuses on preparing data for analysis.
In many cases, data munging is performed on smaller subsets of data that have already been extracted and transformed through an ETL process.
ETL is used to create a clean and structured data foundation upon which data munging can be performed to extract specific insights.